




Ta strona korzysta z ciasteczek, aby zapewnić Ci najlepszą możliwą obsługę. Informacje o ciasteczkach są przechowywane w przeglądarce i wykonują funkcje takie jak rozpoznawanie Cię po powrocie na naszą stronę internetową i pomaganie naszemu zespołowi w zrozumieniu, które sekcje witryny są dla Ciebie najbardziej interesujące i przydatne.

Kategoria:
Sztuczna inteligencja
Branża:
Opieka zdrowotna
Miasto:
Oklahoma, USA
Klient
Klientem projektu jest amerykańska firma z sektora opieki zdrowotnej, która każdego dnia przetwarza ogromne ilości dokumentów finansowych, takich jak potwierdzenia płatności czy rozliczenia z ubezpieczycielami. Większość jej procesów operacyjnych została zautomatyzowana i opiera się na wymianie dokumentów w formacie elektronicznym (takim jak EDIFACT), co zapewnia płynność komunikacji i wysoką efektywność. Problemem pozostawały jednak dokumenty w niestandardowych formatach – skany, wydruki czy dokumenty w formie obrazów – które wymagały manualnej obróbki, ograniczając skalowalność procesu i obciążając zasoby ludzkie.
Wyzwanie
Głównym celem klienta była automatyzacja separacji i klasyfikacji wielostronicowych dokumentów papierowych i skanowanych. Rozwiązanie musiało być odporne na szum informacyjny (np. strony niezwiązane z dokumentem, obrócone skany, różne layouty) i jednocześnie zapewniać wysoką trafność w wykrywaniu granic dokumentów oraz przypisywaniu ich do odpowiednich kategorii. Wymagało to nie tylko zaawansowanego przetwarzania obrazu i tekstu, ale też uwzględnienia specyfiki procesów wewnętrznych klienta.

Rozwiązanie
Projekt zrealizowano w kilku etapach, łącząc eksplorację danych, rozwój modeli machine learningowych (ML) oraz reguły dopasowane do wymagań biznesowych klienta.
W ramach opracowanego rozwiązania uwzględniono:
- Opracowanie modeli wykrywających granice dokumentów w strumieniu stron, które działają na zasadzie binarnej klasyfikacji par stron – system porównuje sąsiadujące strony i ocenia, czy należą do tego samego dokumentu. Pozwala to automatycznie dzielić zbiory stron na właściwe jednostki dokumentów.
- Zbudowanie klasyfikatorów przypisujących dokumenty do odpowiednich kategorii, co umożliwia szybkie skierowanie ich do właściwych procesów lub działów – np. faktury do księgowości, formularze do działu rozliczeń. Dzięki temu unika się ręcznego sortowania i opóźnień.
- Fine-tuning modeli transformerowych, czyli nowoczesnych algorytmów, które potrafią analizować układ i treść dokumentów (Dokument AI) podobnie do człowieka. Ich dostosowanie do danych klienta sprawiło, że system jest dużo bardziej precyzyjny.
- Zaprojektowanie reguł post-processingu, które pomagają dopasować wyniki modelu do realnych potrzeb firmy. Przykład: jeśli dokument nie zawiera konkretnego numeru referencyjnego, może zostać oznaczony do sprawdzenia – mimo że model uznał go za poprawny.
W ramach projektu przeprowadzono również:
- analizę jakości danych i ich eksplorację (EDA),
- filtrację stron zawierających szum informacyjny,
- rozwój i testowanie modeli separacji i klasyfikacji,
- implementację aplikacji integrującej te modele z istniejącymi procesami klienta.
Wszystkie te elementy współdziałają, tworząc elastyczny system, który nie tylko rozpoznaje dokumenty, ale też pomaga w ich dalszym przetwarzaniu zgodnie z ustalonymi procedurami.
Rezultaty
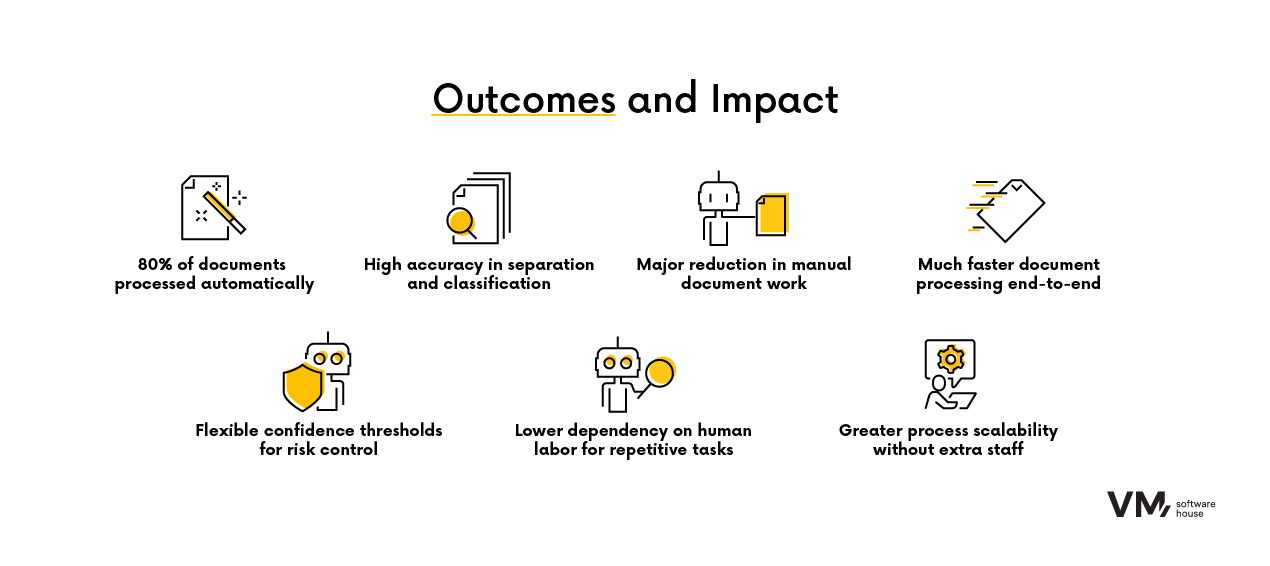
Dzięki wdrożonemu systemowi klient osiągnął znaczące usprawnienia:
- Ponad 80% dokumentów było automatycznie weryfikowanych bez udziału człowieka.
- Osiągnięto bardzo wysoką skuteczność klasyfikacji i wykrywania granic dokumentów na zestawie testowym.
- Znacząco zredukowano czas i nakład pracy potrzebny do manualnego przetwarzania dokumentów.
- Wprowadzono elastyczne progi ufności, umożliwiające dopasowanie poziomu automatyzacji do ryzyka operacyjnego.
Z perspektywy klienta przekłada się to na:
- Zwiększoną skalowalność procesów bez proporcjonalnego wzrostu zatrudnienia,
- Szybsze przetwarzanie dokumentów i płynniejszą obsługę transakcji,
- Mniejsze uzależnienie od zasobów ludzkich w czasochłonnych zadaniach operacyjnych.
Technologie
Rozwiązanie opiera się na najnowszych technikach przetwarzania dokumentów i integracji różnych modalności danych:
- Użycie OCR (rozpoznawanie tekstu), bounding boxes (informacji o położeniu tekstu) oraz skanów graficznych jako wejścia multimodalnego.
- Agregacja embeddingów stron z wykorzystaniem poolingów, warstw uwagi (attention) i Bi-LSTM.
- Separacja dokumentów przy użyciu klasyfikacji binarnej par stron.
- Fine-tuning architektur transformerowych na potrzeby branży opieki zdrowotnej.
Model i jego komponenty zostały w pełni dostosowane do realiów procesów klienta, co przełożyło się na skuteczność rozwiązania i możliwość jego replikacji w innych sektorach, np. logistyce czy administracji, gdzie dokumentacja papierowa nadal odgrywa istotną rolę.

Design, Development, DevOps czy Cloud – jakiego zespołu potrzebujesz, aby przyspieszyć pracę nad swoimi projektami?
Porozmawiaj o swoich potrzebach z naszymi specjalistami.
