






Czy kiedykolwiek zastanawiałeś się, w jaki sposób firmy mogą przewidywać przyszłe trendy i zachowania z dużą dokładnością? Odpowiedzią jest potencjał algorytmów uczenia maszynowego w analityce predykcyjnej.
Uczenie maszynowe rewolucjonizuje sposób, w jaki analizujemy dane i podejmujemy świadome decyzje — od przewidywania cen akcji po wykrywanie nieuczciwych działań.
W tym artykule skupimy się na podstawowych algorytmach ML. Omówimy ich rodzaje, sposób działania oraz kroki związane z tworzeniem i trenowaniem własnych modeli.
Spis treści
Czym są algorytmy uczenia maszynowego?
Algorytmy uczenia maszynowego to modele matematyczne trenowane na danych. Wykorzystują one techniki statystyczne i techniki analizy predykcyjnej w obszarze analizy danych, aby uczyć się wzorców i relacji między danymi, a następnie wykorzystywać tę wiedzę do przewidywania lub podejmowania działań na nowych, niesprawdzonych danych.
Ich główną zaletą jest zdolność ogólnego przetwarzania danych treningowych do nowych, nieznanych wcześniej postaci, co pozwala im na dokonywanie dokładnych prognoz w rzeczywistych scenariuszach.
Kryteria doboru algorytmów uczenia maszynowego
To jaki algorytm należy wybrać, zależy od wielu zmiennych. Nawet najbardziej doświadczeni data scientists nie są w stanie wskazać najlepszego algorytmu przed jego przetestowaniem na określonym zbiorze danych.
Dlatego bez uprzedniego przetestowania kilku algorytmów na zadanym zbiorze danych, wybór jest to w dużej mierze spekulacją. Jest jednak pewien zbiór reguł, który w oparciu o kilka zmiennych pomaga zawęzić Ci poszukiwania do 2-3 algorytmów najlepiej pasujących do konkretnego przypadku. Wskazane algorytmy będziesz mógł przetestować na rzeczywistym zbiorze danych, tak by podjęcie właściwej decyzji było formalnością.
- Typ zadania
Zazwyczaj dostosowujemy metody, zaczynając od najprostszych, żeby w ogóle potwierdzić, że jest sens wchodzić w głębsze i bardziej złożone algorytmy. Przede wszystkim analizujemy to, nad jakim zadaniem pracujemy, czy jest to np. zadanie klasyfikacyjne, w którym chcemy przewidzieć określone kategorie? A może pracujemy nad zadaniem regresji, w którym chcesz przewidzieć wartości ciągłe? Im lepiej zrozumiemy charakter zadania, tym trafniejszy będzie wybór określonego algorytmu.
- Rozmiar i rodzaj danych
Zrozumienie danych jest kluczem do sukcesu. Dlatego zawsze analizujemy, z jakimi konkretnie danymi mamy do czynienia. ponieważ odpowiednie dane dostarczają potrzebnych informacji. Eksploracyjna analiza danych jest zawsze pierwszym krokiem wykonywanym podczas realizacji projektu.
Zrozumienie danych przydaje się również na etapach pośrednich:
•Zanim przejdziemy do czyszczenia danych, zbieramy informacje na temat brakujących wartości.
• Zanim rozpoczniemy transformację danych, musimy wiedzieć jakiego typu zmienne występują w zbiorze.
• Przed rozpoczęciem procesu modelowania, sprawdzamy czy w zbiorze znajdują się obserwacje odstające i zmienne o nietypowych rozkładach.
Niektóre algorytmy lepiej nadają się do małych zbiorów danych, podczas gdy inne mogą efektywnie obsługiwać duże zbiory danych i złożone relacje między zmiennymi .
Jeśli masz mały zbiór danych z prostą relacją między zmiennymi, algorytmy takie jak regresja liniowa lub regresja logistyczna mogą być wystarczające. W przypadku dużego zbioru danych ze złożonymi relacjami, bardziej odpowiednie mogą być algorytmy takie jak lasy losowe lub maszyny wektorów nośnych.
- Interpretacja a wydajność
Innym czynnikiem, który należy wziąć pod uwagę, jest kompromis między możliwością interpretacji a wydajnością. Niektóre algorytmy, takie jak drzewa decyzyjne, pozwalają na interpretację, co oznacza, że dostarczają jasnych wyjaśnień dla swoich prognoz. Inne algorytmy, takie jak sieci neuronowe, mogą osiągać wyższą wydajność, ale brakuje im możliwości interpretacji.
Jeśli możliwość interpretacji jest ważna dla twojego projektu, algorytmy takie jak drzewa decyzyjne lub regresja logistyczna są dobrym wyborem. Jeśli głównym celem jest wydajność, a możliwość interpretacji nie jest priorytetem, bardziej odpowiednie mogą okazać się sieci neuronowe lub modele głębokiego uczenia.
- Złożoność algorytmu
Złożoność algorytmu jest również ważnym czynnikiem. Niektóre algorytmy są stosunkowo proste i łatwe do wdrożenia, podczas gdy inne są bardziej złożone i wymagają zaawansowanych umiejętności programistycznych lub zasobów obliczeniowych.
Jeśli masz ograniczone umiejętności programistyczne, algorytmy takie jak regresja liniowa lub drzewa decyzyjne są dobrym punktem wyjścia. Jeśli masz bardziej zaawansowane umiejętności programistyczne i zasoby obliczeniowe, możesz zbadać bardziej złożone algorytmy, takie jak sieci neuronowe lub modele DL
Biorąc pod uwagę te czynniki, można zawęzić opcje i wybrać odpowiedni algorytm uczenia maszynowego dla swojego projektu. Ważne jest, aby eksperymentować z różnymi algorytmami i oceniać ich wydajność w odniesieniu do konkretnego zadania i danych.
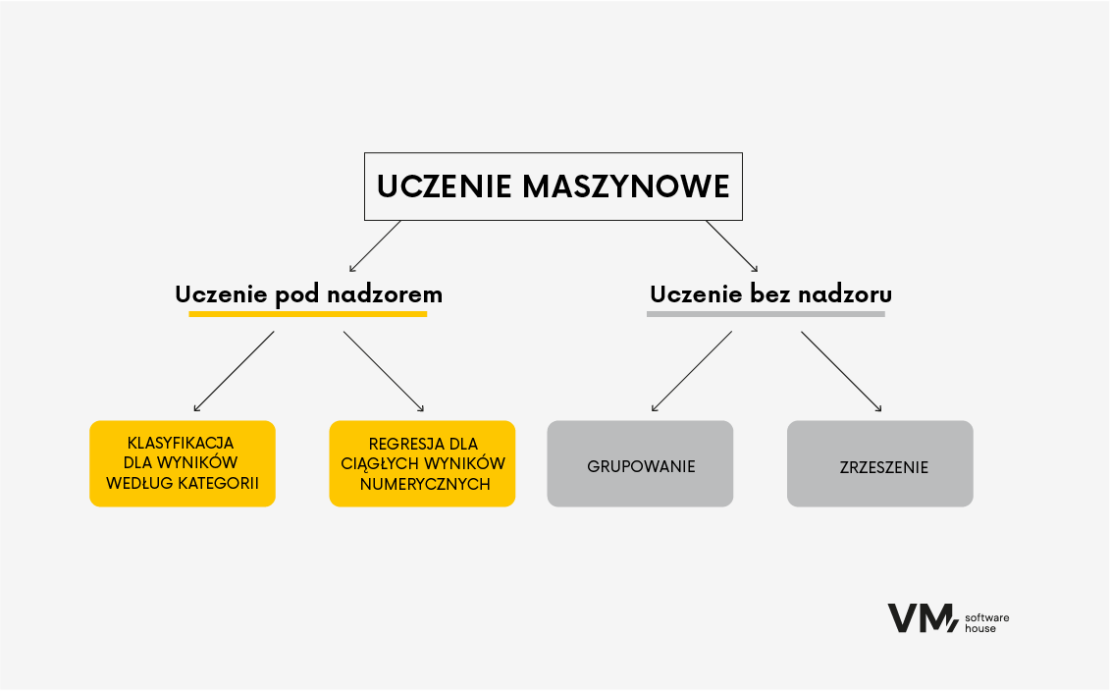
Podział algorytmów w uczeniu maszynowym
Najogólniej można podzielić algorytmy bazując na typie uczenia: nadzorowanym i nienadzorowanym.
Supervised Learning – uczenie pod nadzorem
Algorytmy uczenia nadzorowanego są trenowane na oznaczonych danych, w których dane wejściowe są powiązane z poprawną zmienną wyjściową lub docelową. Algorytm uczy się przyporządkowywać dane wejściowe do właściwych danych wyjściowych poprzez znajdowanie wzorców i relacji w danych. Ten typ algorytmu jest powszechnie stosowany w zadaniach takich jak klasyfikacja i regresja.
Stosujemy algorytmy np. regresji, żeby przewidzieć wartość liczbową na podstawie cech wyjściowych. Wartością tą może być np. szacowana zdolność kredytowa, ryzyko wystąpienia fraudu dla wybranej transakcji, lub też wartość binarna wskazująca czy dany klient banku będzie dobrym czy złym kredytobiorcą. Podsumowując, w tym przypadku dokładnie wiemy czego szukamy i na czym będziemy opierać swe decyzje.
Przykładem może być tu zbiór danych klientów banku, którzy są opisani za pomocą zmiennych takich jak: data urodzenia, numer dowodu osobistego, saldo konta, adres zamieszkania, dane dotyczące historii kredytowej, historia transakcji, etc.
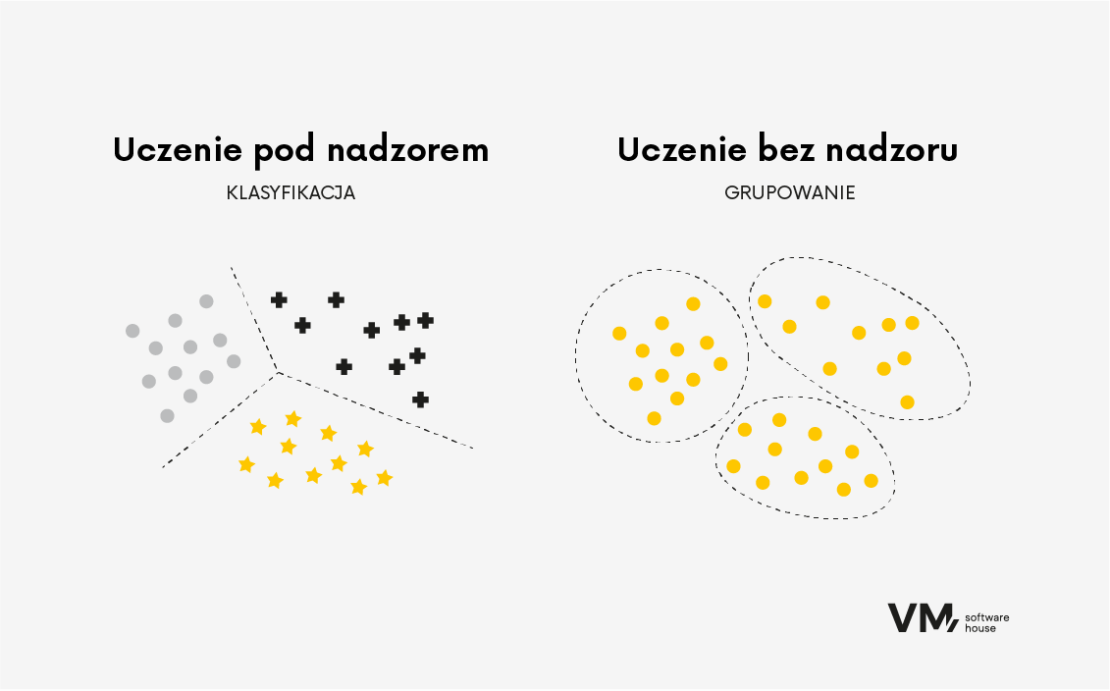
Unsupervised Learning – uczenie bez nadzoru
Algorytmy uczenia nienadzorowanego są szkolone na nieoznakowanych danych, w których dostępne są tylko dane wejściowe bez odpowiadającej im etykiety wyjściowej lub docelowej. Celem uczenia bez nadzoru jest odkrywanie ukrytych wzorców lub struktur w danych. Algorytmy uczenia bez nadzoru są szczególnie przydatne, gdy nie znamy podstawowej struktury danych.
Algorytmy tego typu stosujemy często w takich zadaniach jak grupowanie i redukcja wymiarowości. Na przykład w zadaniach grupowania algorytm grupuje podobne punkty danych na podstawie ich wewnętrznych podobieństw. Może to być przydatne w zadaniach takich jak segmentacja klientów, gdzie algorytm może identyfikować grupy klientów o podobnych preferencjach lub zachowaniach.
Popularne algorytmy uczenia maszynowego
Algorytmy uczenia maszynowego występują w wielu postaciach i formatach, a każdy z nich ma swoje unikalne cechy. W tej części omówimy kilka popularnych algorytmów uczenia maszynowego i ich zastosowanie w różnych branżach.
- Klasyfikacja binarna
W zadaniach klasyfikacji algorytm uczy się klasyfikować dane wejściowe do wcześniej zdefiniowanych dwóch kategorii lub klas.
Klasyfikacja jest używana w takich sytuacjach, jak: wykrywanie obiektów, wszelkiego rodzaju automatyzacje, liczenie obiektów, ale też, chociażby w medycznych kwestiach, na przykład wykrywanie różnych zmian w obrazowaniu medycznym np. kiedy chcemy rozróżnić między osobą chorą a zdrową.
Klasyfikacja binarna obejmuje szkolenie algorytmu w celu przypisania danych wejściowych do wcześniej określonych dwóch kategorii lub klas. Na przykład, algorytm uczenia pod nadzorem można wytrenować w celu określenia czy wiadomość e-mail jest spamem, czy nie, analizując oznaczony zbiór danych wiadomości e-mail. Klasyfikacja binarna jest tam powszechnie używana, ponieważ potrzebujemy przesiać dany zbiór danych i wydzielić dwie grupy.
Na jakie pytania odpowiadają algorytmy klasyfikacyjne? Przykładowo:
- Czy klient będzie dobrym kredytobiorcą? (spłaci kredyt w całości, bez większych opóźnień) | 0,1 (tak lub nie).
- Czy dany klient będzie chciał zrezygnować z naszych usług? | 0,1 (tak lub nie).
- Czy dana transakcja jest fraudem? | 0,1 (tak lub nie).
- Klasyfikacja wieloklasowa
Klasyfikacja wieloklasowa ma miejsce, gdy próbuje się przewidzieć pojedynczy wynik, jak w przypadku klasyfikacji binarnej, ale z więcej niż dwiema klasami. Czasem chcemy rozróżniać coś trochę bardziej skomplikowanego. W przypadku rozróżnienia chorób chcemy np. wiedzieć, którego stopnia jest to nowotwór, w jakim jest stadium albo rozróżnić określony rodzaj nowotworu z większej ilości rodzajów.

Na powyższym obrazku widzimy zastosowanie algorytmów pod nadzorem. Zastosowane metody to:
- KLASYFIKACJA — z pomocą klasyfikacji możemy stwierdzić, że na obrazie jest pies, są zabawki pluszowe, jest kubek.
- WYKRYWANIE OBIEKTÓW — chcemy znaleźć psa, jakiś szczególny kubek dzięki tej metodzie określimy granice obiektu (prostokąt) oraz jakie jest prawdopodobieństwo, że w ramce znajduje się ten określony obiekt.
- SEGMENTACJA — metoda próbująca znaleźć, a następnie zaznaczyć możliwie precyzyjnie poszczególne obiekty, odseparowując je od siebie,
- SEGMENTACJA SEMANTYCZNA – metoda, która zaznacza jako jeden obiekt przedmioty tego samego rodzaju .
- Regresja liniowa
Regresja liniowa to równanie liniowe, które określa związek między różnymi wymiarami.
Algorytm uczy się znajdować najlepiej dopasowaną linię, która minimalizuje sumę błędów kwadratowych między wartościami przewidywanymi i rzeczywistymi. Stosowana jest często w przewidywaniu numerycznym. Przykładem tego jest algorytm, który może przewidzieć wartość domu na podstawie takich cech, jak jego lokalizacja, liczba sypialni i powierzchnia.
Regresja liniowa jest szeroko stosowana w finansach, ekonomii i naukach społecznych do analizy zależności między zmiennymi i tworzenia prognoz. Na przykład może być wykorzystywana do przewidywania cen akcji na podstawie danych historycznych.
- Regresja logistyczna
Regresja logistyczna to popularny algorytm wykorzystywany do przewidywania wyniku binarnego, takiego jak “tak” lub “nie”, na podstawie wcześniejszych obserwacji zbioru danych.
Określa związek między binarną zmienną zależną a jedną lub większą liczbą zmiennych niezależnych poprzez dopasowanie funkcji logistycznej do danych. Algorytm uczy się znajdować najlepiej dopasowaną krzywą, która oddziela dwie klasy.
Regresja logistyczna jest szeroko stosowana w marketingu, opiece zdrowotnej i naukach społecznych do zadań takich jak przewidywanie rezygnacji, wykrywanie oszustw i diagnozowanie chorób. Na przykład, można ją wykorzystać do przewidywania, czy klient prawdopodobnie zrezygnuje z zakupu na podstawie jego wcześniejszych zachowań lub do diagnozowania, czy pacjent cierpi na określoną chorobę na podstawie jego objawów i historii medycznej.
- Drzewa decyzyjne
Drzewa decyzyjne to wszechstronne algorytmy, które mogą być wykorzystywane zarówno do zadań klasyfikacji, jak i regresji. Dzielą one dane na podzbiory w oparciu o wartości cech wejściowych i dokonują prognoz, przechodząc przez drzewo od korzenia do węzła liścia. Zaletą drzew jest interpretowalność wyników predykcji.
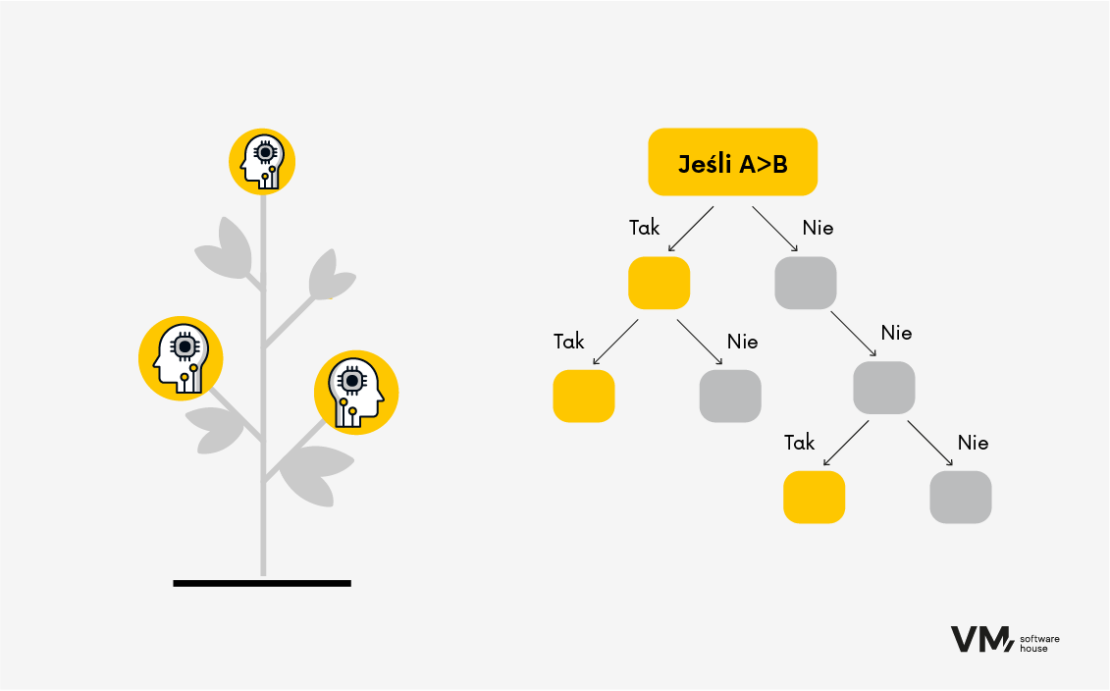
Przykład:
Masz wyniki badań. Chcesz się dowiedzieć więcej:
- Rozdzielenie na płeć: kobieta czy mężczyzna? Jesteś kobietą? Przechodzisz do sekcji poniżej.
- Podział ze względu na wiek. Dzielimy np. Na pięć różnych przedziałów wiekowych:
- 0-18 roku życia
- 18-25 roku życia
- 25-40 roku życia
- 40-55 roku życia
- 55-65 roku życia
- Podział ze względu na cechę wyniku badań (określenie poziomu danego wyniku). Algorytm kieruje Cię krok po kroku, aż na końcu jesteś w ostatnim poziomie, po którym jest określony ostateczny rezultat, nazwany w odpowiedni sposób.
Drzewa decyzyjne uczą się stosunkowo szybko i nie wymagają dużych mocy obliczeniowych. Jednak, aby algorytm umiał to drzewo zbudować w sposób automatyczny i mógł “porozdzielać” odpowiednie poziomy, wymaga to odpowiednio dużej ilości danych, tak by ewentualne błędy były możliwie małe.
Algorytmy te są szeroko stosowane w finansach, marketingu i handlu elektronicznym do zadań takich jak ocena zdolności kredytowej, segmentacja klientów i rekomendacja produktów. Przykładowo, drzewo decyzyjne może być wykorzystywane do przewidywania czy klient ma zdolność kredytową na podstawie jego dochodów, wieku i historii kredytowej, lub do rekomendowania produktów klientom na podstawie ich wcześniejszych zakupów.
- Boosted Decision Tree
Ten algorytm jest wykorzystywany zarówno do zadań klasyfikacji, jak i regresji. Wykorzystuje on koncepcję uczenia zespołowego, w której wiele słabych algorytmów uczących (takich jak płytkie, mające zaledwie kilka poziomów, drzewa decyzyjne) jest łączonych w celu stworzenia dokładniejszego przewidywania. Stopniowe wzmacnianie umożliwia budowanie modeli predykcyjnych sekwencyjnie, gdzie każde drzewo ma na celu przewidzenie błędu pozostawionego przez poprzednie drzewo, to buduje sekwencję drzew. Rezultatem jest bardzo dokładny algorytm, który mimo wszystko wymaga dużej ilości pamięci.
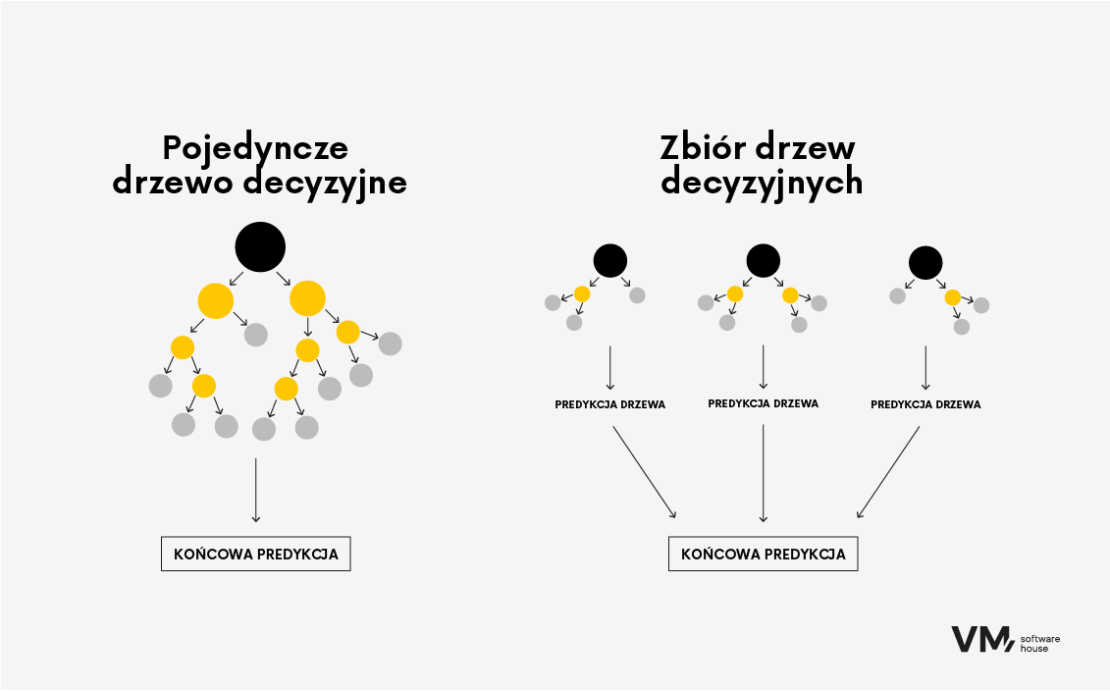
Boosted Decision Tree jest np. Stosowany w bankowości inwestycyjnej, czy systemów oceniających ryzyko kredytowe, czyli wszędzie tam, gdzie liczy się dokładność, nie ma ograniczających zasobów, ew., gdy algorytm nie musi być często uaktualniany.
- Random Forest
Algorytm Random Forest to popularna technika uczenia maszynowego wykorzystywana zarówno do zadań klasyfikacji, jak i regresji. Należy on do metod uczenia zespołowego, w których buduje się wiele drzew decyzyjnych podczas szkolenia i łączy je w celu uzyskania dokładniejszej i stabilniejszej prognozy.
To tak jakby połączyć grupę zróżnicowanych ekspertów współpracujących przy podejmowaniu decyzji. Każdy model wnosi swoje spostrzeżenia, a razem osiągają lepszą wydajność niż jakikolwiek pojedynczy model. Główną zaletą lasów losowych jest większa dokładność modelu niż w przypadku drzewa decyzyjnego, ponieważ im bardziej zróżnicowane jest źródło informacji, tym solidniejszy jest losowy las, ponieważ nie będzie ulegał wpływom pojedynczego anomalnego źródła danych.
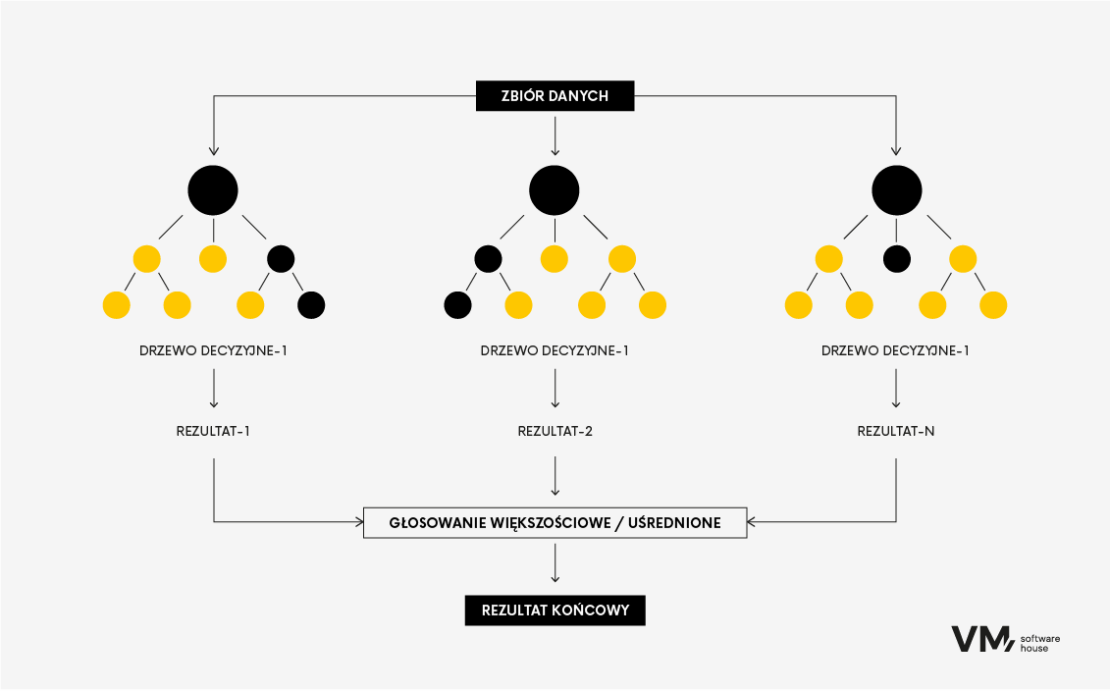
Minusem tej metody jest fakt, że potrzebuje dużych zasobów danych, więc może być kosztowna obliczeniowo. Najczęściej stosuje się ją w bankowości inwestycyjnej czy systemach oceny ryzyka kredytowego.
- Sieci neuronowe
Jest to jeden z bardziej wyrafinowanych algorytmów spośród wszystkich, które przedstawiamy w tym artykule. Jest inspirowany działaniem ludzkiego mózgu, przez naśladowanie procesów, w jaki neurony biologiczne współpracują ze sobą w celu identyfikowania zjawisk, ważenia opcji i wyciągania wniosków.
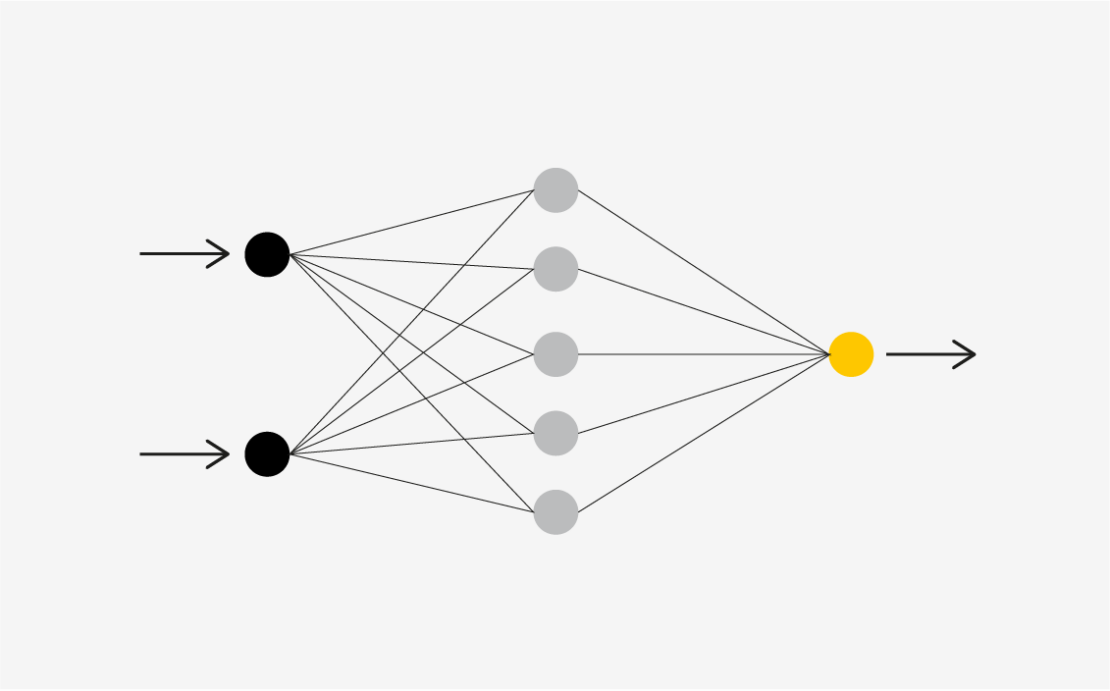
Sieci neuronowe są zbudowane przy użyciu sztucznych komórek mózgowych zwanych jednostkami. Jednostki te współpracują ze sobą w celu uczenia się, rozpoznawania wzorców i podejmowania decyzji w sposób podobny do ludzkiego mózgu. Sposób działania sieci neuronowych można przyrównać do połączenia mocy komputera z gęsto połączonymi komórkami mózgu.
Sposób działania
Komputery wykorzystują tranzystory — małe urządzenia przełączające. Nowoczesne mikroprocesory zawierają ponad 50 miliardów tranzystorów, ale są one połączone w stosunkowo proste, szeregowe łańcuchy. Tranzystory są połączone w podstawowe układy znane jako bramki logiczne. Sieci neuronowe naśladują połączenia realnych neuronów, łącząc sztuczne komórki mózgowe (jednostki) w warstwy.
Najczęściej ta metoda jest stosowana przy złożonych problemach z dużymi zbiorami danych, w problemach, w których ciężko dopatrzeć się prostych wzorców. Jej główną zaletą jest fakt, że potrafi uczyć się skomplikowanych wzorców, nadaje się do zadań głębokiego uczenia. Natomiast utrudnieniem jest fakt, że wymaga ona znacznych zasobów obliczeniowych (GPU) i obszernych danych treningowych.
Sieci neuronowe są wykorzystywane w różnych dziedzinach:
- Rozpoznawanie obrazów: Identyfikacja i znajdowanie obiektów na obrazach.
- Przetwarzanie języka naturalnego: Rozumienie i generowanie ludzkiego języka.
- Systemy rekomendacji: Spersonalizowane sugestie (np. rekomendacje Netflix).
- Diagnostyka medyczna: Wykrywanie chorób na podstawie obrazów medycznych.
- Prognozy finansowe: Trendy giełdowe, ocena ryzyka kredytowego itp.
Uczenie maszynowe – jaka jest przyszłość analityki predykcyjnej?
Modele analizy predykcyjnej odgrywają kluczową rolę w dziedzinie prognozowania, ponieważ dzięki analizie ogromnych ilości danych historycznych organizacje mogą przewidywać przyszłe wyniki z dużą dokładnością.
Stanowią też podstawę strategicznego podejmowania decyzji i optymalizacji operacyjnej w różnych branżach. Niezależnie od tego, czy chodzi o usprawnienie inspekcji sanitarnych w restauracjach, rozwiązywanie złożonych wyzwań biznesowych, czy dostosowywanie strategii marketingowych, możliwość przewidywania przyszłych wyników oznacza ogromny postęp w sposobie, w jaki dane wpływają na postęp i innowacje.
Wdrażając algorytmy uczenia maszynowego, możesz dokonywać dokładnych prognoz na podstawie nowych, niewidocznych danych. Ważne jest, aby regularnie przeprowadzać iteracje i udoskonalać proces w odniesieniu do konkretnych wymagań danego projektu. Jeśli chciałbyś o tym porozmawiać ze specjalistami od AI/ML, zapraszamy do kontaktu.




